Real-time Stable Markerless Tracking for Augmented Reality Using Image Analysis/Synthesis Technique
Augmented Reality (AR) developed over the past decade with many applications in entertainment, training, education, etc. Vision-based marker tracking of subject is a common technique used in AR applications over the years due to its low-cost and supporting freeware libraries like AR-Toolkit. Recent research tries to enable markerless tracking to get rid of the unnatural black/white fiducial markers which are attached a subject being tracked. Common markerless tracking techniques extract natural image features from the video image streams. However, due to perspective foreshortening, visual clutter, occlusions, sparseness and lack of texture [1], feature detection approaches are inconsistent and unreliable in different scenarios.
This project explores a markerless tracking technique using image analysis/synthesis approach. Its task is to minimize the relative difference in image illumination between the synthesized and captured images. Through the use of a 3D geometric model and correct illumination synthesis, it promises more robust and stable results under different scenarios. However, speed and efficient initialization are its biggest concerns. The aim of our project is to investigate and produce robust real-time markerless tracking. The speed can be enhanced by reducing the number of iterations via different optimization techniques. Graphics Processors (GPU) will be exploited to accelerate the rendering and optimization by making use of parallel processing capabilities. The outcome of this project includes new reusable software modules for AR, VR, HCI applications.
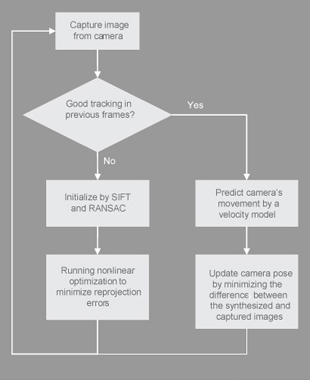
The workflow of our markerless tracking algorithm is illustrated in figure 1. To initialize the tracking process, SIFT feature matching and RANSAC-based robust method is used. Once the camera pose has been initialized, as the camera does not change a lot between two consecutive frames, the new camera pose can be quickly updated from the pose in the previous frame. A velocity model will be used first to estimate the new pose. This estimated pose will be used to synthesize a projection image of the object. After that, the pose will be iteratively updated by minimizing the differences between the synthesized and captured images. If this optimization fails, the algorithm will try to initialize again by matching SIFT features.
Automatic Initialization: In order to implement real-time tracking, object recognition is needed to find a given object in the sequence of video frames.
For any object in an image, there are many 'features' which are interesting points on the object that can be extracted to provide a "feature" description of the object. This description extracted from a training image can then be used to identify the object when attempting to locate the object in a video frame that containing many other objects. It is important that the set of features extracted from the training image is robust to changes in image scale, noise, illumination and local geometric distortion, for performing reliable recognition.
With the arrival of dedicated graphics hardware with increasing computational power and programmability, we were able to implement SiftGPU [3], GPU-based feature detection into our application. SiftGPU is an implementation of Scale Invariant Feature Transform (SIFT) in GPU, which able to run at very high speeds by porting the existing CPU algorithms to the GPU. Therefore we can achieve better performance in real-time detection and matching in terms of frame rates.
Using SiftGPU, we are able to extract keypoints from the input image of the object to be track and perform matching with the sequences of video frames. Once there are enough successfully matches, we applied RANSAC-based robust method to calculate the homography matrix between the image of the frame and image of the object. Then we able to estimate the 3D pose and draw a virtual 3D object on the top of the real object.
Some illustrative results:
We demonstrate our application that able to perform real-time tracking and pose estimation using a rectangular object and the steps are shown in the images below.

Fig 2.The steps of tracking a rectangular object. (a) Feature points are detected and matched with the keypoints of the input image. (b) The 4 comers of the face are detected using the matched points. (c) The 3D pose is calculated and a virtual rectangle is drawn. Our real-time tracking application not only robust to illuminations changes, translation, scaling and rotation changes, it also performs well with occlusion as shown in the images below.

Figure 3. The detection is (a) invariance with respect to translation scaling and rotation, (b) changes in illuminations and (c) partial occlusion. We can make some preliminary conclusions that problems with some products as the features detected are insufficient for matching. We see also that the materials of product packaging can be too glossy and cause reflection, leading to blurred capture images. We also are continuing to solve the problems with jittering of the virtual object. We are exploring increases in the frame rate by improving the speed of detection and matching processes.

Fig 4. The six faces of our test rectangular object are detected and the estimated 3D pose of rectangular box is shown.
Research conceived and developed by Lee Shang Ping, directed by Russell Pensyl with Tran Cong Thien Qui and Li Hua. Initially developed in the Interaction and Entertainment Research Centre, Nanyang Technological University, Singapore.
2. Kindberg, T. Ubiquitous and contextual identifier resolution for the real-world wide web, Proceedings of the 11th international conference on World Wide Web Pages: 191 - 199. 2002
3. Varodayan, D.and Ghosh K. Visual Code Marker Detection. Journal of Computers. Vol. 1, No. 3, 2006
4. Tina T. Dong, Visual Code Marker Detection. http://scien.stanford.edu/2006projects/ee368/Project/ee368_reports/ee368group25.pdf
5.http://en.wikipedia.org/wiki/Feature_detection_ (computer_vision)
6. Easkins J. and Graham M. Content-based Image Retrieval. University of Northumbria at Newcastle. 1999
7. Lehrer J. “How We Decide”. Houghton Mifflin Co. 2009
8. Miller, G. A. "The magical number seven, plus or minus two: Some limits on our capacity for processing information". Psychological Review 63(2): pp 81-97. 1956
9. Hick, William E.; On the rate of gain of information. Quarterly Journal of Experimental Psychology, 4, pp 11-26, 1952
10. Lepetit V., Fua P. Keypoint Recognition using Randomized Trees, Transactions on Pattern Analysis and Machine Intelligence, Vol. 28, Nr. 9, pWp. 1465 - 1479, 2006
11. Lepetit V., Lagger P. and Fua P. Randomized Trees for Real-Time Keypoint Recognition, Conference on Computer Vision and Pattern Recognition, San Diego, CA, June 2005
12. Tran C. T. Q, Lee S. P., Loy S. C. and Pensyl W. R. Tiger Training Augmented Reality. Proceedings of the seventeen ACM international conference on Multimedia, 2009
13. Lowe, D. Distinctive Image Features from Scale Invariant Keypoints. International Journal of Computer Vision, 20(2):91–110, 2004
14. Wu, C. SiftGPU: A GPU Implementation of Scale Invariant Feature Transform (SIFT), http://www.cs.unc.edu/~ccwu/siftgpu/. 15. Lucas B. and Kanade T. An iterative image registration technique with an application to stereo vision, in International Joint Conference on Artificial In6elligence, pp. 674679, 1981
16. Open computer vision library. http://sourceforge.net/projects/opencvlibrary/
17. Jianbo, S, and Tomasi, C., Good features to track, Computer Vision and Pattern Recognition, 1994. Proceedings CVPR ’94., 1994 IEEE Computer Society Conference on , vol., no., pp.593-600, 21-23 Jun 1994
18. Q.C.T. Tran, S.P. Lee, W.R. Pensyl, D. Jernigan, Robust Hybrid Tracking with Life-size Avatar in Mixed Reality Environment, Proceedings of the 3rd International Conference on Virtual and Mixed Reality: Proceedings of the HCI International 2009